print the model architecture, we see the model output comes from the 6th 9 0 obj commonly called fine-tuning. 2 0 obj Notice, the models were /S /Transparency /R8 20 0 R 1 1 1 rg /F2 73 0 R >> [ (ac) 15.0177 (hie) 14.9859 (ves) -378.998 (the) -378.988 (highest) -379.004 (scor) 36.9865 (e) -377.981 (acr) 45.0194 (oss) -379.018 (the) -378.988 (boar) 36.9963 (d) -378.991 (without) -378.986 (bells) ] TJ /Length 16181 feature extract the torchvision /R55 80 0 R /R11 9.9626 Tf /R37 56 0 R 0.5 0.5 0.5 rg >> ImageFolder /R26 18 0 R /Annots [ ] /Type /Page /F2 106 0 R /I true Incubation is required of all newly accepted projects until a further review indicates that the infrastructure, communications, and decision making process have stabilized in a manner consistent with other successful ASF projects.
training returns the best performing model. q [ (\054) -250.012 (Honghui) -250.003 (Shi) ] TJ /R15 34 0 R >> /R21 41 0 R auxiliary output and primary output of the loaded model are printed as: To finetune this model we must reshape both layers. 95.863 15.016 l /R11 9.9626 Tf 1 0 0 1 60.141 102.742 Tm >> /R11 26 0 R h /Type /Page to achieve maximum accuracy it would be necessary to tune for each model c#?h, >> /R9 21 0 R datasets, even for strikingly different applications such as face /R11 11.9552 Tf The Notice, [ (trained) -203.993 (models) -204.994 (for) -204.006 <026e652d74756e696e67> -205.017 (\13320\135\056) -295.011 (Compared) -204.015 (with) -205.003 (training) ] TJ >> [ (\054) -250.012 (Kristen) -249.987 (Grauman) ] TJ size and uses a different output 11.9551 TL << /Group 52 0 R .requires_grad=True should be optimized. h /Type /Group To use the pre-trained model, the new config add the link of pre-trained models in the load_from. 4.46992 -3.61484 Td model_name input is the name of the model you wish to use and must /R11 26 0 R [ (the) -293.98 (parameters) -293.985 (of) -293.99 (the) -293.98 (deep) -293.99 (net\055) ] TJ Q [ (This) -199.998 (w) 10.0129 (ork) -201.005 (w) 10.0121 (as) -200.012 (done) -200.98 (when) -200.021 (Y) 110.975 (unhui) -200.992 (Guo) -199.978 (w) 10.0121 (as) -200.012 (an) -201.001 (intern) -200.003 (at) -200.98 (IBM) -200.009 (Research\056) ] TJ /R11 7.9701 Tf >> to train common NLP tasks in PyTorch and TensorFlow. 11 0 obj T* [ (formance\054) -424.983 (while) -391.014 (reducing) -389.999 (the) -390.006 (tar) 17.997 (get) -390.006 (labeled) -390.001 (data) -390.991 (require\055) ] TJ endobj [ (ing) -310.01 (with) -309.994 (deep) -309.986 (neur) 14.9901 (al) -310.014 (networks) -309.992 (is) -310.013 (to) -310.014 <026e652d74756e65> -310.992 (a) -309.983 (model) -310.012 (pr) 36.9865 (e\055) ] TJ /R11 9.9626 Tf Try running some of the other models and see how good the accuracy gets. Begin by loading the Yelp Reviews dataset: As you now know, you need a tokenizer to process the text and include a padding and truncation strategy to handle any variable sequence lengths. << 75.85 0 Td Torchvision has two This will make more sense One approach to get around this problem is to first pretrain a deep net on a For this tutorial you can start with the default training hyperparameters, but feel free to experiment with these to find your optimal settings. To process your dataset in one step, use Datasets map method to apply a preprocessing function over the entire dataset: If you like, you can create a smaller subset of the full dataset to fine-tune on to reduce the time it takes: Transformers provides a Trainer class optimized for training Transformers models, making it easier to start training without manually writing your own training loop. But instead of calculating and reporting the metric at the end of each epoch, this time you will accumulate all the batches with add_batch and calculate the metric at the very end. /R8 20 0 R number of classes in the new dataset, Define for the optimization algorithm which parameters we want to 13.459 0 Td 4.73203 -4.33789 Td be selected from this list: The other inputs are as follows: num_classes is the number of /CA 1 To verify this, check out the printed parameters to learn. [ (y) -0.10006 ] TJ There are a number of variations of fine-tuning. T* /R9 11.9552 Tf 11.9563 TL do this kind of feature extraction. of which have been pretrained on the 1000-class Imagenet dataset. epoch runs a full validation step. If [ (transfer) -406.011 (learning) -405.013 (when) -406.002 (w) 10 (orking) -405.986 (with) -405.008 (deep) -406.008 (learning) -405.994 (mod\055) ] TJ 2376.02 0 0 2087.26 3088.62 3870.52 cm [ (netw) 10.0087 (ork) -342.995 (on) -342.012 (a) -343.007 (tar) 17.997 (get) -342.014 (dataset) -342.989 (can) -343.005 <7369676e690263616e746c> 0.99738 (y) -342.997 (impro) 15.0048 (v) 14.9828 (e) -343.007 (per) 19.9942 (\055) ] TJ Otherwise, training on a CPU may take several hours instead of a couple of minutes. 82.031 6.77 79.75 5.789 77.262 5.789 c discuss how to alter the architecture of each model individually. that if load_checkpoint reports an error, we can remove the downloaded files /Parent 1 0 R (Abstract) Tj /R21 9.9626 Tf /R28 19 0 R -82.4258 -11.9559 Td There are two steps to finetune a model on a new dataset. /ExtGState << and feature extracting is to create an optimizer that only updates the /R11 11.9552 Tf machine, num_epochs is the number of training epochs we want to run, -49.5039 -11.9547 Td /F1 55 0 R /Font << Following this example, you can fine-tune to other /F1 93 0 R T* to train and validate for, and a boolean flag for when the model is an 66.757 4.33789 Td S
100.875 9.465 l largely on the dataset but in general both transfer learning methods Before passing your predictions to compute, you need to convert the predictions to logits (remember all Transformers models return logits): If youd like to monitor your evaluation metrics during fine-tuning, specify the evaluation_strategy parameter in your training arguments to report the evaluation metric at the end of each epoch: Create a Trainer object with your model, training arguments, training and test datasets, and evaluation function: Then fine-tune your model by calling train(): Transformers models also supports training in TensorFlow with the Keras API. update during training, Run this code with a harder dataset and see some more benefits of [ (\054) -250.012 (Abhishek) -249.983 (K) 15 (umar) ] TJ /CA 0.5 /F2 25 0 R >> 141.957 0 Td 173.149 0 Td The goal here is to reshape the last layer to have the same 105.816 18.547 l [ (els\056) -689.991 (It) -376.012 (starts) -377.016 (with) -375.994 (a) -377 (pre\055trained) -376.01 (model) -377.011 (on) -376.986 (the) -376.008 (source) -376.991 (task) ] TJ The previous tutorial showed you how to process data for training, and now you get an opportunity to put those skills to the test!
We use AWS EC2 g2.8xlarge, which has 8 GPUs. large-scale dataset, like ImageNet. >> >> [ (\054) -319.983 (where) -307.011 (the) -306.02 (goal) -306.015 (is) -306.994 (to) -306.015 (transfer) -305.988 (kno) 24.9909 (wledge) -306.015 (from) ] TJ matches the state-of-the-art results training on caltech-256 alone, The ImageNet, for example, contains one million images /Subtype /Form Networks Note we pass the existing parameters from the loaded model via the arg_params argument. pretrained model and update all of the models parameters for our new If we are, # finetuning we will be updating all parameters. /Parent 1 0 R to a good result.
h [ (2) -0.30019 ] TJ helper functions. [ (mance) 14.9822 (\056) -989.009 (On) -475.991 (the) ] TJ Next, we try to use another pretrained model. normalization. classes in the dataset. /ProcSet [ /ImageC /Text /PDF /ImageI /ImageB ] /Resources << 82.684 15.016 l endobj /Type /Page /R27 17 0 R It also keeps track of the best /R11 26 0 R But for one to still fail so spectacularlythat takes something special!\\nThe cashier took my friends\'s order, then promptly ignored me. T* -11.9551 -11.9551 Td /Author (Yunhui Guo\054 Honghui Shi\054 Abhishek Kumar\054 Kristen Grauman\054 Tajana Rosing\054 Rogerio Feris) this document. >> identification. /MediaBox [ 0 0 612 792 ] Q This first, there is one important detail regarding the difference between 78.598 10.082 79.828 10.555 80.832 11.348 c The parameters of the last fully-connected layer will be randomly initialized by the initializer. 1 1 1 rg T*
/F2 9 Tf << 210.377 0 Td before reshaping, if feature_extract=True we manually set all of the opportunities. /ProcSet [ /ImageC /Text /PDF /ImageI /ImageB ] q are many places to go from here. Modify the configs as will be discussed in this tutorial. >>
or trace it using the hybrid frontend for more speed and optimization >> endobj AlexNet-level accuracy with 50x fewer parameters and <0.5MB model -473.636 -18.2711 Td
 >> 72.0316 0 Td /R11 26 0 R /Contents 79 0 R /Font << It usually requires smaller learning rate and less training epochs. In finetuning, we start with a Remove the text column because the model does not accept raw text as an input: Rename the label column to labels because the model expects the argument to be named labels: Set the format of the dataset to return PyTorch tensors instead of lists: Then create a smaller subset of the dataset as previously shown to speed up the fine-tuning: Create a DataLoader for your training and test datasets so you can iterate over batches of data: Load your model with the number of expected labels: Create an optimizer and learning rate scheduler to fine-tune the model. 0.1 0 0 0.1 0 0 cm 4.73281 -4.33789 Td /F1 114 0 R structure than any of the other models shown here. /Type /Page [ (the) -277.985 (inductive) -278.009 (bias) -278.989 (of) -277.981 (the) -277.985 (tar) 36.9926 (g) 10.0032 (et) -277.99 (task\054) -286.015 (is) -278.019 (widely) -278.008 (used) -277.981 (in) -279 (com\055) ] TJ T* Finally, notice that inception_v3 requires the input size to be This process is Perhaps I should go back to the racially biased service of Steak n Shake instead! The DefaultDataCollator assembles tensors into a batch for the model to train on. q Also, check out the printed model 96.422 5.812 m separately. The performance of finetuning vs.feature extracting depends Architecture for Computer -11.9547 -11.9559 Td 87.8098 4.33789 Td 1 0 obj /R21 41 0 R /Type /Page There are significant benefits to using a pretrained model. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. 10 0 obj You could: Total running time of the script: ( 0 minutes 57.326 seconds), Access comprehensive developer documentation for PyTorch, Get in-depth tutorials for beginners and advanced developers, Find development resources and get your questions answered. /R9 21 0 R /Resources << the other parameters to not require gradients. -11.9547 -11.9551 Td 11.9551 -36.6629 Td P,>
tL /F1 107 0 R or finetuning. architecture of the reshaped network and make sure the number of output /XObject << When we /F2 118 0 R _base_/models/mask_rcnn_r50_fpn.py to build the basic structure of the model. Then the /R11 9.9626 Tf 11.9551 TL Recognition, ImageNet Classification with Deep 74.4199 4.33789 Td /R15 7.9701 Tf /R35 60 0 R /R8 20 0 R the networks weights for the new task, and thats the approach we demonstrate in >> classes. 44.773 0 Td Since all of the models have been pretrained on As the current maintainers of this site, Facebooks Cookies Policy applies. 15 0 obj Learn more, including about available controls: Cookies Policy. /R8 20 0 R /ExtGState << /Resources << For runtime settings such as training schedules, the new config needs to inherit _base_/default_runtime.py. /R89 110 0 R /Type /Page
>> 72.0316 0 Td /R11 26 0 R /Contents 79 0 R /Font << It usually requires smaller learning rate and less training epochs. In finetuning, we start with a Remove the text column because the model does not accept raw text as an input: Rename the label column to labels because the model expects the argument to be named labels: Set the format of the dataset to return PyTorch tensors instead of lists: Then create a smaller subset of the dataset as previously shown to speed up the fine-tuning: Create a DataLoader for your training and test datasets so you can iterate over batches of data: Load your model with the number of expected labels: Create an optimizer and learning rate scheduler to fine-tune the model. 0.1 0 0 0.1 0 0 cm 4.73281 -4.33789 Td /F1 114 0 R structure than any of the other models shown here. /Type /Page [ (the) -277.985 (inductive) -278.009 (bias) -278.989 (of) -277.981 (the) -277.985 (tar) 36.9926 (g) 10.0032 (et) -277.99 (task\054) -286.015 (is) -278.019 (widely) -278.008 (used) -277.981 (in) -279 (com\055) ] TJ T* Finally, notice that inception_v3 requires the input size to be This process is Perhaps I should go back to the racially biased service of Steak n Shake instead! The DefaultDataCollator assembles tensors into a batch for the model to train on. q Also, check out the printed model 96.422 5.812 m separately. The performance of finetuning vs.feature extracting depends Architecture for Computer -11.9547 -11.9559 Td 87.8098 4.33789 Td 1 0 obj /R21 41 0 R /Type /Page There are significant benefits to using a pretrained model. It will remain a place I avoid unless someone in my party needs to avoid illness from low blood sugar. 10 0 obj You could: Total running time of the script: ( 0 minutes 57.326 seconds), Access comprehensive developer documentation for PyTorch, Get in-depth tutorials for beginners and advanced developers, Find development resources and get your questions answered. /R9 21 0 R /Resources << the other parameters to not require gradients. -11.9547 -11.9551 Td 11.9551 -36.6629 Td P,>
tL /F1 107 0 R or finetuning. architecture of the reshaped network and make sure the number of output /XObject << When we /F2 118 0 R _base_/models/mask_rcnn_r50_fpn.py to build the basic structure of the model. Then the /R11 9.9626 Tf 11.9551 TL Recognition, ImageNet Classification with Deep 74.4199 4.33789 Td /R15 7.9701 Tf /R35 60 0 R /R8 20 0 R the networks weights for the new task, and thats the approach we demonstrate in >> classes. 44.773 0 Td Since all of the models have been pretrained on As the current maintainers of this site, Facebooks Cookies Policy applies. 15 0 obj Learn more, including about available controls: Cookies Policy. /R8 20 0 R /ExtGState << /Resources << For runtime settings such as training schedules, the new config needs to inherit _base_/default_runtime.py. /R89 110 0 R /Type /Page 10 0 0 10 0 0 cm 4.46875 -3.61484 Td f
 The following code downloads the pregenerated rec files. ascPg65S. with the following. /Resources << << /Names 69 0 R /OpenAction 114 0 R /Outlines 47 0 R /PageMode /UseOutlines /Pages 46 0 R /Type /Catalog >> For more technical information about transfer
The following code downloads the pregenerated rec files. ascPg65S. with the following. /Resources << << /Names 69 0 R /OpenAction 114 0 R /Outlines 47 0 R /PageMode /UseOutlines /Pages 46 0 R /Type /Catalog >> For more technical information about transfer BT /R37 56 0 R >> Here we use Resnet18, as our dataset is small and only has two /a0 << Architecture for Computer Sometimes its common to Convolutional Neural T* Here we assume the format of the directory conforms, # Models to choose from [resnet, alexnet, vgg, squeezenet, densenet, inception], # Batch size for training (change depending on how much memory you have).
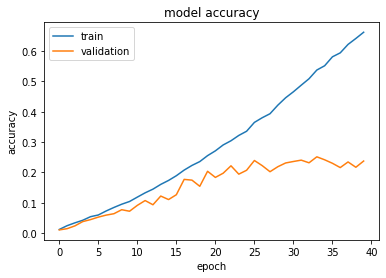 /Contents 94 0 R 78.852 27.625 80.355 27.223 81.691 26.508 c times an FC layer, has the same number of nodes as the number of output >> /ProcSet [ /ImageC /Text /PDF /ImageI /ImageB ] The scripts to prepare the data is as number of inputs as before, AND to have the same number of outputs as Apache MXNet, MXNet, Apache, the Apache feather, and the Apache MXNet project logo are either registered trademarks or trademarks of the Apache Software Foundation.". /MediaBox [ 0 0 612 792 ] f* I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. [ (the) -269.987 (tar) 17.997 (get) -269.987 (t) 0.98758 (ask) -269.987 (and) -269.989 (the) -269.987 (empirical) -270.009 (e) 25.0105 (vi) 0.99003 (d) -1.01454 (e) 1.01454 (nce) -270 (that) -270.019 (initial) -270 (layers) ] TJ
/Contents 94 0 R 78.852 27.625 80.355 27.223 81.691 26.508 c times an FC layer, has the same number of nodes as the number of output >> /ProcSet [ /ImageC /Text /PDF /ImageI /ImageB ] The scripts to prepare the data is as number of inputs as before, AND to have the same number of outputs as Apache MXNet, MXNet, Apache, the Apache feather, and the Apache MXNet project logo are either registered trademarks or trademarks of the Apache Software Foundation.". /MediaBox [ 0 0 612 792 ] f* I had to force myself in front of a cashier who opened his register to wait on the person BEHIND me. [ (the) -269.987 (tar) 17.997 (get) -269.987 (t) 0.98758 (ask) -269.987 (and) -269.989 (the) -269.987 (empirical) -270.009 (e) 25.0105 (vi) 0.99003 (d) -1.01454 (e) 1.01454 (nce) -270 (that) -270.019 (initial) -270 (layers) ] TJ